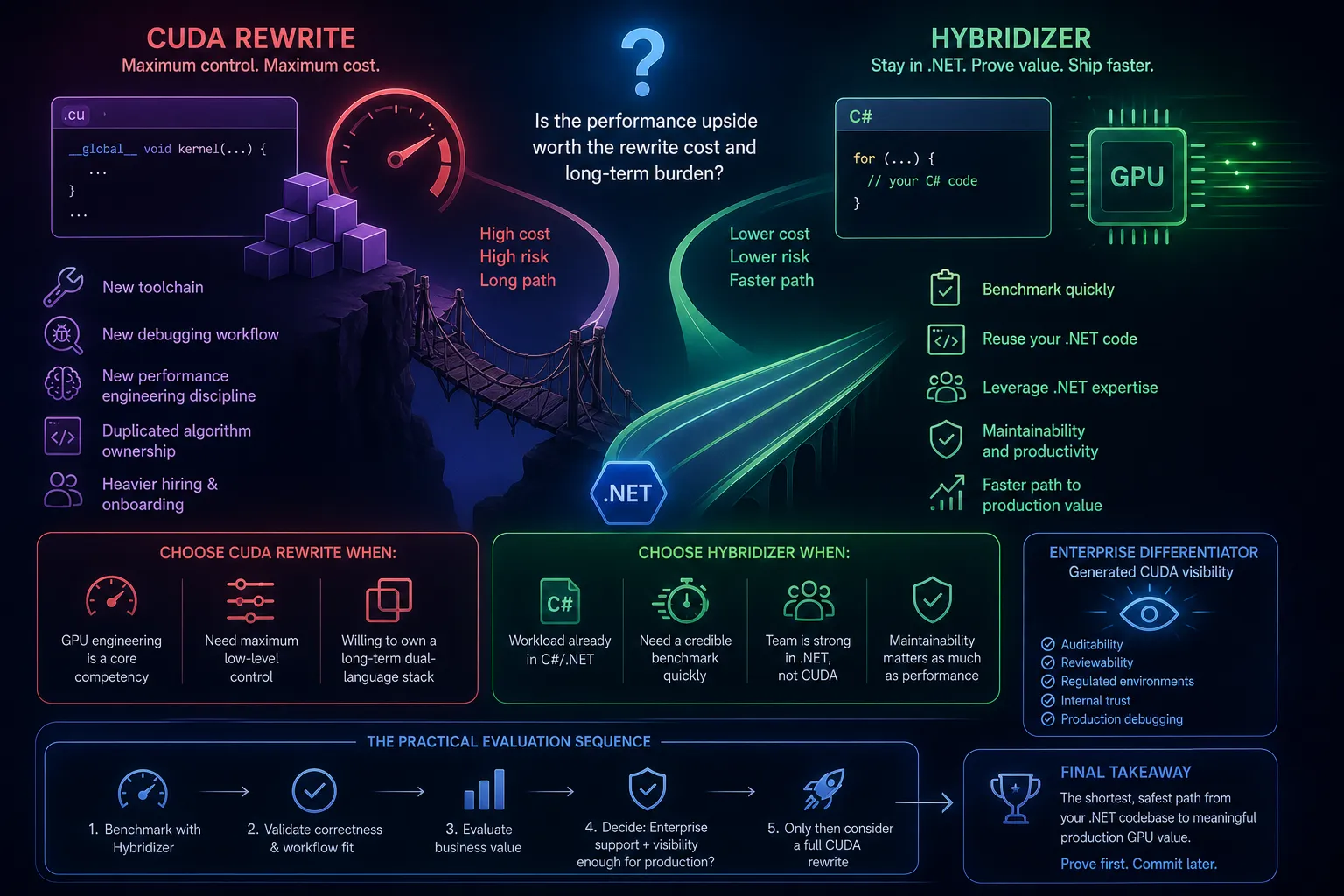
When a .NET team discovers a compute bottleneck, the loudest suggestion in the room is often: “If we really care about performance, we should just rewrite it in CUDA.”
Sometimes that is correct. Often it is not.
The real decision is not “CUDA or no CUDA.” It is whether the expected performance upside justifies the rewrite cost, workflow disruption, and long-term maintenance burden.
What a CUDA rewrite really means
A rewrite to CUDA C++ is not only a language change. It usually means all of the following:
- a new toolchain
- a new debugging workflow
- a new performance engineering discipline
- duplicated algorithm ownership across languages
- heavier hiring and onboarding constraints
That can be worth it for teams whose business already runs on hand-tuned GPU engineering. It is often overkill for teams that simply need a faster path from .NET code to production GPU value.
Where Hybridizer changes the economics
Hybridizer is attractive because it changes the first question from:
“How fast can we become a CUDA shop?”
to:
“How fast can we prove whether this .NET workload deserves GPU acceleration at all?”
That is a very different business problem.
Choose Hybridizer when these are true
1. The workload already lives in C#/.NET
If the algorithm already exists in your .NET codebase, staying close to that source of truth dramatically reduces adoption friction.
2. You need a credible benchmark quickly
Hybridizer is a better first move when the company needs evidence before approving a major rewrite.
3. Your team is strong in .NET, not CUDA
This is common in finance, insurance, enterprise software, and simulation teams.
4. Maintainability matters as much as raw peak performance
A code path that multiple .NET engineers can understand and evolve is often more valuable than a highly specialized rewrite that only a small number of experts can touch.
Choose a CUDA rewrite when these are true
1. GPU engineering is already a core competency
If you already have a strong CUDA practice, the cost of a rewrite may be acceptable.
2. You need maximum low-level control everywhere
Some workloads demand aggressive manual optimization beyond what most teams need for first production success.
3. You are willing to own a long-term dual-language stack
That means tooling, hiring, debugging, and maintenance overhead are all accepted costs.
The hidden cost most teams underestimate
The biggest mistake is focusing only on runtime performance and ignoring delivery performance.
A rewrite has at least two timelines:
- time to benchmark
- time to production
Hybridizer often wins because it compresses both.
If your team can get from “we found a bottleneck” to “we proved a credible GPU path” in days or weeks instead of quarters, that changes how innovation happens inside the company.
The practical evaluation sequence
For most .NET organizations, the best sequence is:
- benchmark the workload with Hybridizer
- validate correctness and workflow fit
- evaluate business value
- decide whether Enterprise support and generated CUDA visibility are enough for production
- only consider a full rewrite if the residual gap still matters
This sequence keeps the expensive decision until after you have evidence.
Why generated CUDA visibility matters here
A common concern from engineering leaders is control.
They worry that a productive path from C# to GPU will become a black box. That is exactly why generated CUDA visibility matters as an Enterprise differentiator.
It gives teams a more credible story for:
- auditability
- reviewability
- regulated environments
- internal trust
- production debugging and optimization conversations
Final takeaway
The question is rarely “Is CUDA powerful?” Of course it is.
The real question is:
What is the shortest, safest path from our current .NET codebase to meaningful production GPU value?
If your team needs proof before committing to a rewrite, Hybridizer is usually the smarter first move.